
一、NLP&神经网络
要理解Transformer,就要先了解自然语言处理(NLP: Natural Language Processing)以及神经网络(NNs: Neural Network)的发展史。因为Transformer的提出, 正是为了解决循环神经网络(RNN: Recurrent neural network)在处理自然语言上遇到的性能问题。
自然语言处理是人工智能和语言学领域的分支学科,而神经网络在语言构建模型、机器翻译等领域被广泛应用。 神经网络的发展经历了人工神经网络(ANNs: artificial neural network) -> 前馈神经网络(feedforward neural network) -> 卷积神经网络(CNN: Convolutional neural network) -> 循环神经网络(Recurrent neural network) -> Transformer几个重要的过程。
前馈神经网络最早发明的简单人工神经网络类型。与循环神经网络不同的是: 在它内部参数从输入层向输出层单向传播,它不会构成有向环。
卷积神经网络用于处理网格状数据。它通常包含卷积层、池化层和全连接层。卷积层用于提取特征,池化层用于减小数据的空间维度,全连接层用于输出分类或回归结果。由于卷积操作的并行性,CNN在训练和推理时可以更容易地进行并行化。这使得它们在大规模数据上的处理更加高效。因此卷积神经网络主要用于图像识别、计算机视觉任务、图像分类等。
本系列主要讨论时间序列或自然语言等序列数据操作相关的内容,因此CNN相关内容不做过多叙述。
循环神经网络适用于自然语言处理、语音识别、时间序列预测等需要考虑序列依赖关系的任务,相关内容可以查看斯坦福大学RNN相关的课程介绍。
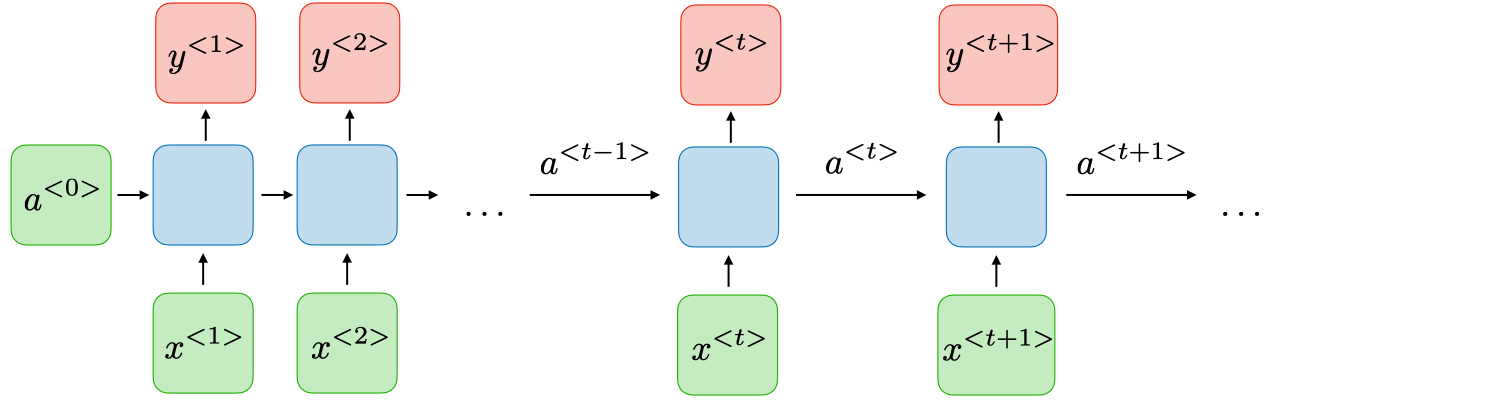
简单的说,在RNN模型里有三个重要的概念:输入层X(t)、输出层Y(t)以及隐藏层A(t)。Y(t)依赖输入层X(t)和上一轮的隐藏层A(t-1)得到A(t)。所以公式上可以简化为:
Y(t) = G(a) * A(t) + G(b), A(t) = G(a) * A(t-1) + G(b) * X(t) + G(c) G(x): 为损失函数的系数,这个可以根据不同算法,进行微调以满足模型的不同结果。
由于RNN是随时间更新的隐藏状态的,所以距离当前时间越长,越早输入的序列,在更新后的状态中所占权重越小,从而表现出时间相关性。
这就好比我们小时候玩的传话游戏:输入层是老师,隐藏层是传话的同学,输出层是最后写到黑板上的结果。
 根据每个同学的传话特点,我们有可能能完整的把意思表达出来,但也可能完全丢掉传话内容,甚至出现一些奇怪的信息。
根据每个同学的传话特点,我们有可能能完整的把意思表达出来,但也可能完全丢掉传话内容,甚至出现一些奇怪的信息。 RNN模型同样表现出来相似的特点。RNN虽然在处理序列数据方面具有优势(得到正确输出),但也存在一些缺点(传递失真及耗时):
梯度消失和梯度爆 RNN 的训练过程中容易遇到梯度消失或梯度爆炸的问题。这是由于在反向传播中,通过时间反向传播梯度时,连乘的效应可能导致梯度变得非常小或非常大,从而使权重更新几乎没有效果或者过分剧烈。
长期依赖关系难以捕捉 传统的 RNN 面临难以捕捉长期依赖关系的问题。在处理长序列时,信息在每个时间步传递时可能会逐渐衰减,导致模型难以记住先前的信息。
计算效率低 RNN 的计算效率相对较低,因为它们在每个时间步都需要进行序列的前向传播和反向传播。这使得对长序列进行训练变得更加耗时
Transformer提出Attention机制,较好的解决循环神经网络的问题。同时,并行处理能够大大的提升训练的效率。
那么到底什么是Transfomer,它又经历了哪些发展过程呢?请看下个章节。
二、 Transformer
Transformer是一种用于序列到序列学习的深度学习模型架构,由Vaswani等人在2017年的论文《Attention is All You Need》中首次提出。该模型采用了自注意力机制(Self-Attention),通过注意力机制在输入序列的不同位置分配不同的权重,从而能够有效地捕捉序列中的长距离依赖关系。
该论文发表后,Facebook AI团队迅速通过pyTorch框架实现了Transformer模型,并在WMT14英译德语数据集上取得了很好的效果。
至此,机器学习迎来类爆发性的进展。Facebook、openai、google以及百度等团队相继推出了不同Transformers优化模型。虽然新的 Transformer 模型层出不穷,它们采用不同的预训练目标在不同的数据集上进行训练,但是依然可以按模型结构将它们大致分为三类:
- 纯 Encoder 模型(例如 BERT),又称自编码 (auto-encoding) Transformer 模型;
- 纯 Decoder 模型(例如 GPT),又称自回归 (auto-regressive) Transformer 模型;
- Encoder-Decoder 模型(例如 BART、T5),又称 Seq2Seq (sequence-to-sequence) Transformer 模型。
Transformer 的出现推动了自然语言处理领域的发展,成为许多任务的基础,包括机器翻译、文本生成、文本分类等。它的成功也激发了后续各种变体和改进,成为深度学习领域中的重要里程碑之一。
Transfomer里多次提到注意力机制,那么它又到底是什么呢?我们来看一下论文内容
三、Attention Is All You Need
差生入门机器学习,很多生僻词都是通过维基检索学习。如果有不表达不正确的地方,希望各路大神能指出。
随着研究人员逐渐意识到引入注意力机制可以提高模型性能。注意力机制开始被引入到循环神经网络中,以增强模型对序列中不同位置信息的关注能力。这种组合通常被称为Attention-based RNN,因此不是Transformer才用到注意力机制。
3.1 简介 (Introduce)
第一段: 作者先表达了对RNN、LSTM、GRU在语言模型和机器翻译中的认可,称赞了研究人员为突破循环语言模型和ecoder-decoder架构边界作出的努力。
第二段: 作者开始吐槽RNN的不足之处,见上方缺点介绍。 😂 RNN要维护一个隐状态,该隐状态取决于上一时刻的隐状态。这种内在的串行计算特质阻碍了训练时的并行计算(特别是训练序列较长时,每一个句子占用的存储更多,batch size变小,并行度降低)。 尽管很多研究都在做这一块的优化,但隐藏层串行这一本质并无法改变。这一段隐藏了Transformer设计的一个动机:解决并发训练的效率
第三段: 介绍了注意力机制设计的另一个目的:允许序列化、转换模型,在做自然语言处理的时候,无视输入输出队列上顺序(步距)问题。作者也说了,在少数情况下也需要考虑顺序距离问题,可以在RNN的基础上加入注意力机制。
第四段: 作者完全丢弃了循环架构,新提出了transfomer架构。这个新的架构完全依赖注意机制,来建立输入和输出之间的全局依赖关系。 并且作者在8个A100GPUs上训练了12个小时,得到了一个非常好的自然语言理解成绩。
3.2 背景 (Background)
第一段:说明减少串行计算隐藏层,同样是卷积神经架构(ByteNet、ConvS2S)和神经图灵机(Extended Neural GPU)的诉求.而使用Transfomer来减少串行顺序计算,虽然减少了操作次数,但是带来了有效分辨率的下降。因此作者引入了多头注意力机制(Multi-Head Attention)。
第二段: 注意力机制又被称为内部注意力机制,因为它只关联注意单个序列中的不同位置。自注意力已成功应用于各种任务,包括阅读理解、提取性摘要、文本蕴涵和学习与任务无关的句子表示。
第三段: 端到端记忆网络基于循环注意机制,而不是循环的序列对齐。它已经在简单语言问答和语言建模任务上表现良好。
第四段: 忽略,营养价值不高。
3.3 Transfomer架构
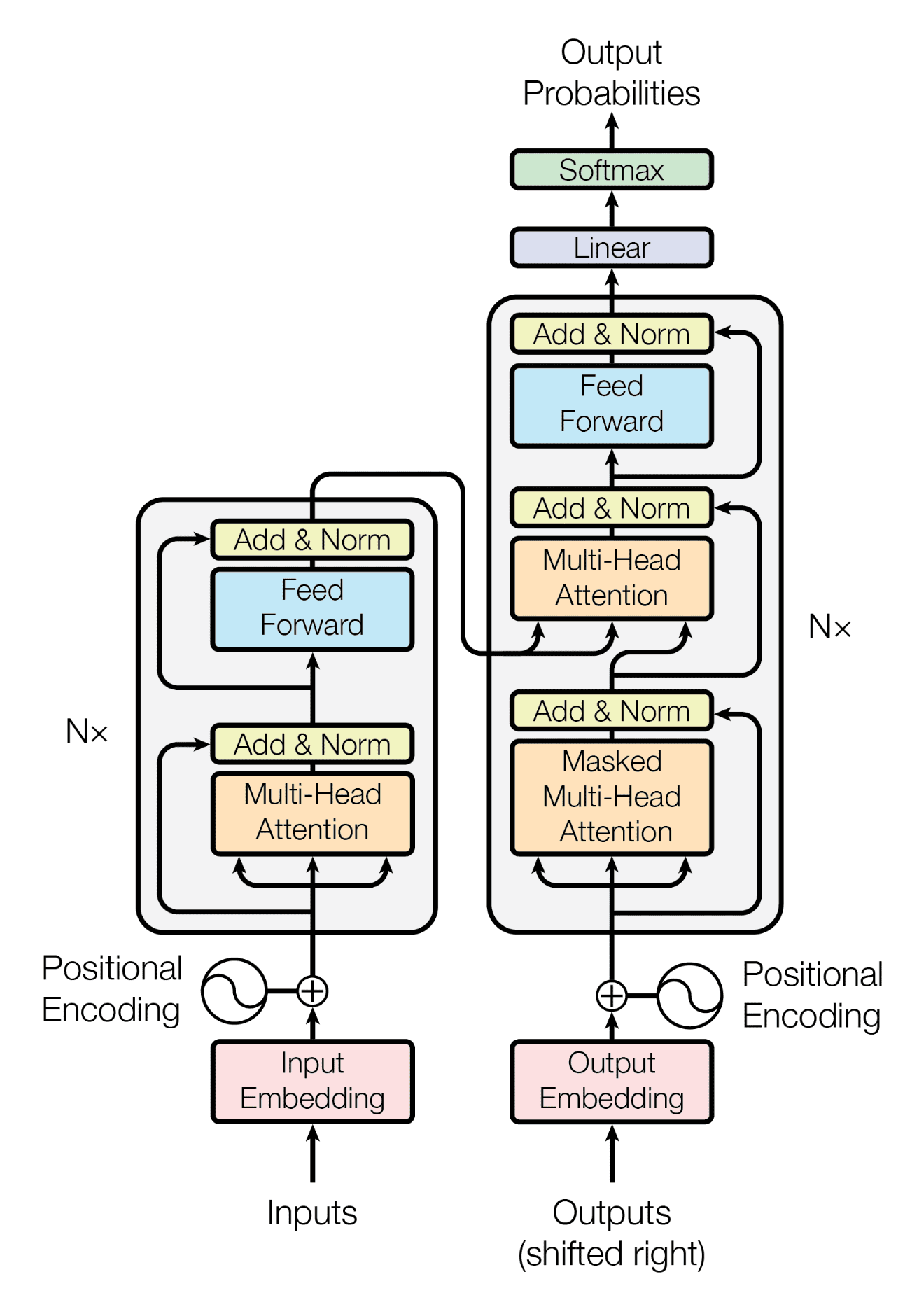
自注意力机制(Self-Attention)
允许模型在处理序列时动态地关注序列中的不同位置,而无需先验知识。
多头注意力(Multi-Head Attention)
将自注意力机制应用于多个头,使得模型可以学习不同的关注方式,更好地捕捉不同类型的关系。
位置编码(Positional Encoding)
用于为输入序列的每个位置提供位置信息,因为自注意力机制本身不具备处理序列中位置信息的能力。
前馈神经网络层(Feedforward Neural Network)
在每个注意力层后接了一个前馈神经网络层,增强模型的非线性建模能力。